深度学习对很多行业来说是破坏性的技术,但该技术的计算要求可以超越标准 CPU。这一问题一直激励着开发人员考虑替代性的架构,但从类似的 CPU 迁移至更加深奥的设计是一项十分具有挑战性的工作。这样,组织不需要改造已有基础设施来支持深度学习,而是只需使用混合 CPU + FPGA 计算架构即可。
即使是从性能的角度考虑,用户也可以从使用混合 CPU 中获益。比如说,很多此类处理器可以高效地执行单独的深度学习推理工作负载,因为单独的推理是顺序操作。但是,如果推理操作包批或大量出现,则 CPU 速度很难跟上。
GPU 和其他大规模并行架构提供了串行处理的一种替代性方案。大量并行架构非常适合分批处理推理工作负载,和培训带有大量输入数据集的深度学习模式。
当然,对于顺序处理,并行计算机的速度通常难以跟上。对于需要快速按顺序推理的应用,如自主车辆计算机视觉和其他时间敏感型应用,GPU 可能不是十分适合。
要满足小量推理和大批量处理的需求,能够将 FPGA 与多核 CPU 集成的设备是不错的选择。由于 FPGA 在性质上是大量并行架构,因此能够执行大量深度学习批次。同时,CPU 也可以处理较少的顺序操作。或者,FPGA 与 CPU 之间可以共享工作负载,以优化神经网络的效率。
另外,由于此异构架构具有架构灵活性,因此无需改造已有计算基础设施,即可优化效率。
使用 FPGA 进行 AI 加速:串联和协同处理
为了更好地理解 FPGA 如何加速深度学习,我们首先来了解 FPGA 如何作为串联和协同处理计算要素与多核 CPU 一同工作。
作为串联处理器,FPGA 位置在 CPU 前面,它在传输输出数据进行进一步计算前执行预处理任务,如数据过滤。如图 1 所示,视觉系统可以使用 FPGA,在发送像素到 CPU 之前,进行串联过滤或阈值化。由于 CPU 仅处理 FPGA 确定的关注区域的像素,因此整个系统的吞吐量将增加。
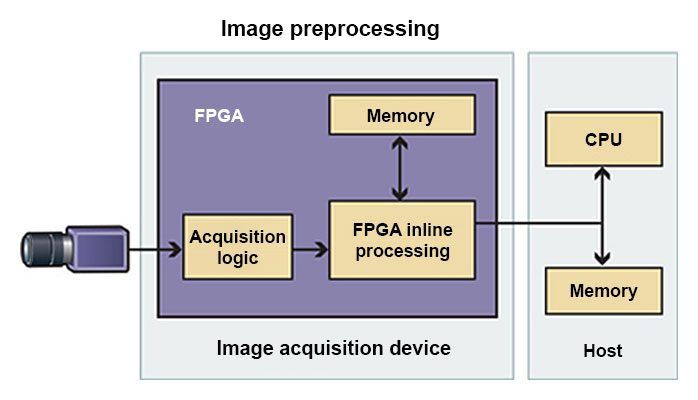
图 1. 作为串联处理器,FPGA 可以在数据传输到 CPU 之前对其进行过滤,从而帮助提升整个系统的吞吐量。(信息来源:National Instruments)
作为协处理器,FPGA 将与 CPU 共享计算工作负载。共享可以通过多种方式实现:在将输出数据发送回 CPU 前,由 FPGA 执行并行处理;也可以由 FPGA 执行所有处理工作,这样 CPU 可以重点处理通信和控制等工作。
我们来继续了解计算机视觉的示例,图 2 显示了 FPGA 与 CPU 之间如何通过直接内存访问 (DMA) 分布工作负载。
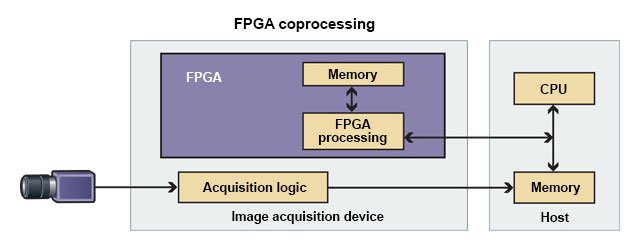
图 2.
FPGA 协处理器可以通过直接内存访问 (DMA) 与 CPU 共享工作负载,从而将 CPU 解放出来处理其他任务。(信息来源:National Instruments)
总结来说,将 FPGA 与多核 CPU 配对可以满足进行小量推理和更大规模分批处理的同时增加系统吞吐量的需求。但是,开发人员必须能够保证在对已有基础设施影响最小的情况下,采纳这些解决方案。
新版 FPGA 交付极佳性能与集成灵活性
英特尔® Stratix® 10 FPGA 能够提高深度学习性能,同时简化与已部署系统的集成。这些 FPGA 最多可以集成 550 万个逻辑单元和一个四核 64 位 Arm Cortex-A53 CPU。FPGA 还可以提供允许 FPGA 轻松地与标准网络和计算技术连接的 I/O pin 码。
在性能方面,Intel Stratix 10 设备使用新款英特尔® HyperFlex™ FPGA 架构设计。该架构采纳了超级注册技术,将可由支线输送的注册放置到设备核心的各个路由段以及所有功能块输入(图 3)。
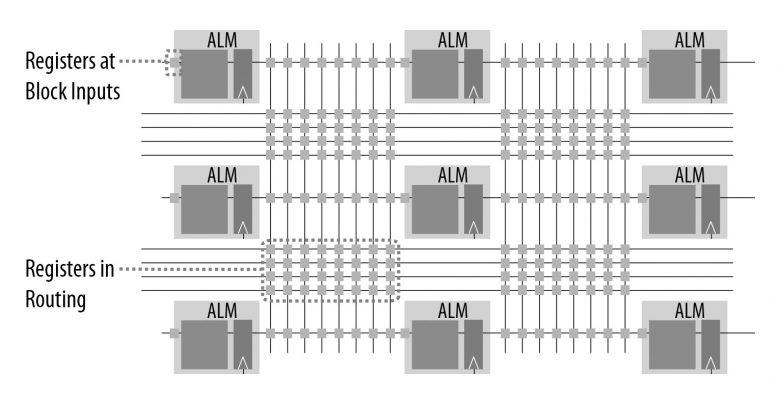
图 3. 超级注册将注册放置到各个路由段和所有功能块输入,以推动时钟频率翻倍。(资料来源:英特尔® 公司)
可由支线输送的注册可优化 FPGA 架构各处的数据流,可帮助芯片实现性能最大化。因此,与上一代 FPGA 相比,英特尔 Stratix 10 设备能够在耗电量减低 70% 的情况下,提供双倍的时钟速度。这一伟大的改进使得 FPGA 非常适合需要提高性能,但供电量有限的应用场景。
在平台集成方面,英特尔 Stratix 10 FPGA 设备支持串行和并行闪存接口。这些内存类型在网络平台上十分常见,非常适合用于深度学习,因为这些内存类型可让开发人员选择最适合其工作负载的配置。例如,Terasic, Inc. 的 DE10-Pro Stratix 10 GX/SX PCIe Board 支持各种应用的多种类型的内存(图 4):
- 适合用于高带宽、低延迟应用场合的 QDR-IV 内存模块
- 适合用于狄艳池内存读写的 QDR-II+ 内存模块
- 适合用于需要有最大内存容量的应用场景的 DDR4

图 4. Terasic, Inc. 的 DE10-Pro Stratix 10 GX/SX PCIe Board 支持为不同的深度学习用例使用多种内存类型。(资料来源:Terasic, Inc.)
DE10-Pro 包含用于芯片间数据传输速度最快达 128 Gbps 的 x16 PCIe Gen 3 个通道,而四个 QSFP28 连接器都支持 100 千兆位以太网。这些接口可实现大量数据卸载,还可快速读写内存。在服务器或数据中心环境中,这意味着工作负载可以在计算库与内存资源之间共享,从而按需要调整深度学习性能。
最后,从软件角度看,DE10-Pro Stratix 10 GX/SX PCIe Board 支持英特尔® Open Visual Inference 和 Neural Network Optimization(英特尔® OpenVINO™)工具套件。OpenVINO 是适合异构执行架构使用的开发套件,它基于能够将 FPGA 编程的复杂性抽象化的通用 API。
OpenVINO 包括 OpenCV 和 OpenVX 的很多功能、内核和优化调用,为计算机视觉和深度学习工作负载展示了性能的强化,最高可达 19x(图 5)。
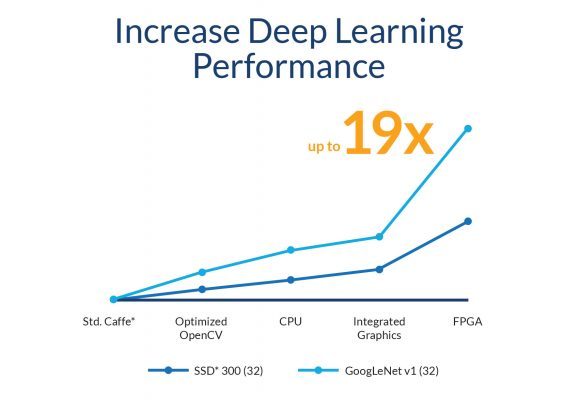
图 5. Open Visual Inference 和 Neural Network Optimization (OpenVINO™) 工具套件展示了性能的显著优化。(资料来源:英特尔® 公司)
更快加速
一般而言,深度学习工作负载正推动该技术领域不断创新;特别是,它推动着数据处理市场的创新。该行业当前正在挖掘新的方法,以通过使用神经网络专用的处理器来计算深度学习工作负载。
拥有集成多核 CPU 的 FPGA 具有灵活性和高性能,能够在可获得最高吞吐量的地点、时间并以这种方式执行深度学习工作负载。这些 FPGA 还可提供未来需求的迁移路径,前提是这些需求涉及人工智能、下一代网络或任何可通过高性能计算 (HPC) 应对的细分市场。