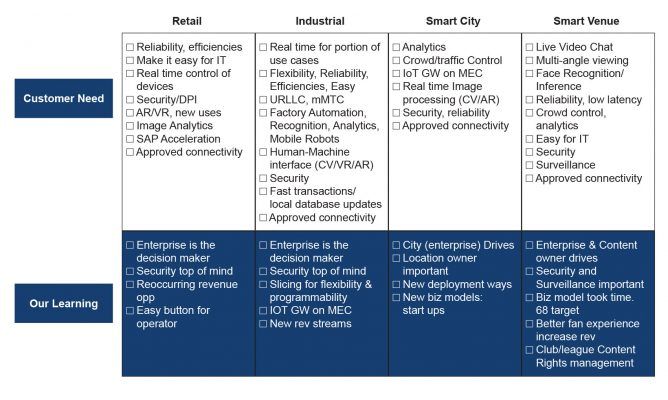
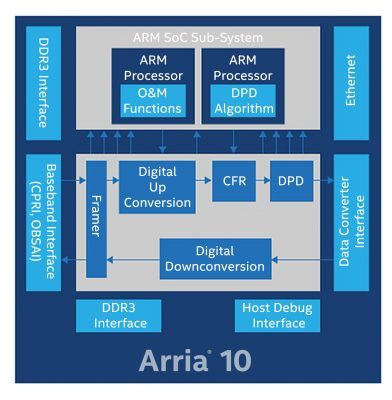
在过去的十年里,我们看到技术发展比上一个十年迅速得多,就好比激流飞瀑比之涓涓细流。物联网中数目庞大的分布式系统催生了 5G 时代的新功能。这些连接的设备生成的大数据推动了有助于让分析自动进行的 AI 的兴起。
每一个渐进的发展都伴随着计算需求的增加。因此,各种类型和规模的数据驱动型组织发现他们需要高性能计算 (HPC) 平台。
我们来看一下对系统工程师的影响。
逐级走向边缘分析:5G 案例研究
我们看一下 5G 网络的需求。国际电信联盟 (ITU) 在 2017 年宣布,5G 移动蜂窝移动网络必须实现每平方千米支持多达 100 万个设备。它们还必须提供至少为 20 Gbps 的总下载容量和 10 Gbps 总上传容量。相比之下,4G 小蜂窝移动网络每平方英里支持大约 100,000 个设备,峰值数据速率约为 1 GBps。
图 1 显示了大都市圈预计的 5G 网络数据密度。为了防止如此大量的数据堵塞回程网络,运营商多半会鼓励在更靠近网络边缘的位置进行更大型的数据分析。运营商如果不采用 5G 边缘分析战略,那么他们很可能需要为此付出代价:他们需要为他们所生成的大量数据支付更高的传输成本。
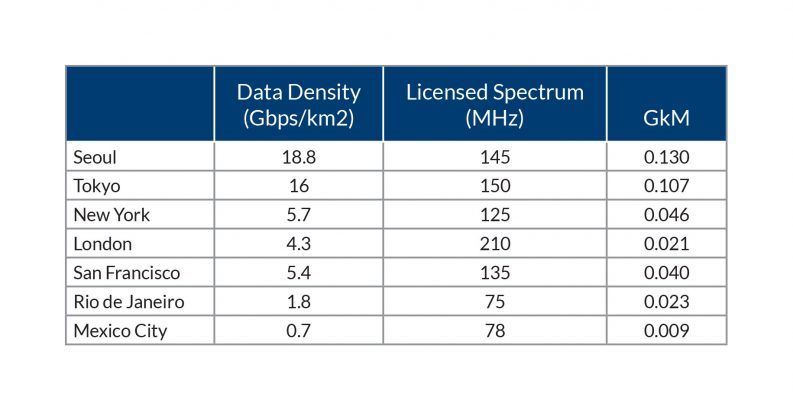
图 1. 建议的 5G 的数据密度要求在边缘网络中有更高的处理和存储性能用于分析,在市区中尤其如此。(资料来源:Fierce Wireless)
但是,庞大的数据量使得将分析移到边缘困难重重。5G 边缘分析的工作负载堪比通常驻留在云中或数据中心中的那些大数据系统的工作负载。在云中或数据中心中,工作负载可以分散在大量的计算、存储和网络资源中。相比之下,5G 分析必须以更轻量化的方式分布在海量边缘网络端点中。
以 AI 为中心的性能提升
让 5G 边缘分析普遍盛行的一个解决方案是 AI,因为可使用它来让中大规模的数据筛选跨 5G 基础设施自动进行。引入启用 AI 的流量过滤来满足这些网络工作负载的快速变化的需求需要可扩展的多核解决方案。在这方面,英特尔® 至强TM 可扩展处理器是一个优势选项。
英特尔至强可扩展处理器为 HPC 平台提供一项工艺:可提供 4 至 28 个内核和 1 至 8 个插槽的配置。举例来说,在有 8 个插槽的系统中,英特尔至强白金器件最多可支持 224 个内核。
这些处理器还可提供许多 HPC 友好的功能,在高内核数量之外锦上添花。例如,它们可集成英特尔® 高级矢量扩展 512(英特尔® AVX-512)。这些 512 位矢量指令每个时钟周期可以执行 32 个双精度浮点运算或 64 个单精度浮点运算。根据特定指令集,该技术还可以添加多达两个积和熔加运算单元,加快数学密集型运算的速度。
在主成分分析 (PCA) 等使用案例中,英特尔 AVX 512 可提供明显的优势。可以使用这种机器学习方法来将一组值转换为线性变量,而线性变量可由网络运营商用于了解流量形态,可由企业用于获得大数据见解。
PCA 可使用热门的机器学习 (ML) 库(如在 Apache Spark 上运行的 MLlib)来执行。但是,MLlib 可能会迅速被较大的数据集困住。使用英特尔 AVX 512 的库(如英特尔® 数据分析加速库(英特尔® DAAL)可解决这个问题。如图 2 中所述,用 PCA 的 MLlib 代码实施对英特尔 DAAL 的几个简单调用可导致明显的工作负载加速,并且随着数据集大小增加,速度提高更为明显。
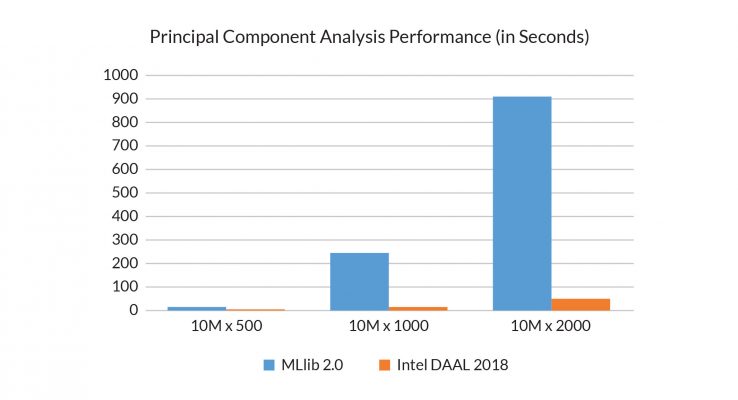
图 2.
在 Apache Spark 上运行的 MLlib 机器学习 (ML) 库可在数据分析中用于主成分分析 (PCA),但是当数据集大小增长时,它的性能不能很好地随之增长。(资料来源:英特尔®)
这些处理器还具备经过重新配置的网格高速缓存和内存架构,这不但可以降低延迟,而且可以加快访问数据集的速度,这正是 AI 和大数据分析应用所需的。此外,与上一代处理器相比,这些器件还可增加了 50% 的内存通道和 20% 的 PCIe 通道,以支持较小规模的计算群集。
让 5G 数据保持流动
上述种种只是可让 5G 及其他 HPC 应用获益的功能的开端。例如,5G 网络要承载的数据流量的数量和密度不断增加,催生了不同服务质量 (QoS) 的需要。英特尔® 虚拟化技术(英特尔® VT)允许将内核分配给不同流量类型的特定控制和数据平面网络任务。
此外,5G 必须支持的更大节点数目需要这样的交换结构:不但支持的设备数比目前多,而且性能或可靠性有增无减。英特尔® Omni-Path 架构(英特尔® OPA)结构支持超过 10,000 个节点,同时还能够在以明显高很多的 8 字节消息传递接口 (MPI) 速率传输数据的情况下,误码率 (BER) 比 InfiniBand 增强的数据速率 (EDR) 低几个数量级(图 3)。
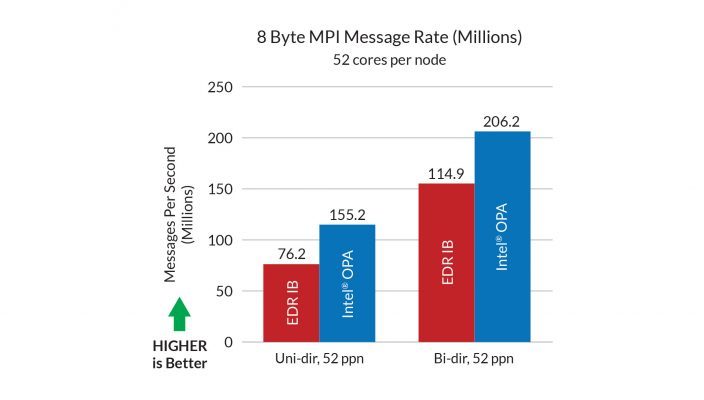
图 3. 与 InfiniBand 增强的数据速率 (EDR) 相比,英特尔® Omni-Path 架构(英特尔® OPA)可提供明显高很多的 8 字节消息传递接口 (MPI) 速率。(资料来源:英特尔®)
为了帮助随着流量增大而扩展 5G 边缘计算能力,工程师转向诸如 WIN Enterprises 生产的 PL-81890 HPC 之类的平台。PL-81890 HPC 是一个高密度控制服务器,配置两枚英特尔至强铂金或金牌可扩展处理器和 12 个存储器托架,整合到紧凑的 2U 机箱中(图 4)。该系统还支持 WIN Enterprise 的可信平台控制模块,以帮助保持处理敏感通信的系统的完整性。

图 4. WIN Enterprises PL-81890 HPC 是一个 2U 可信平台,适用于高要求的 5G、数据分析和人工智能任务。(资料来源:WIN Enterprises)
可将 OPA Host Fabric 接口适配器卡插入到诸如 PI-81890 HPC 之类的平台中(通过使用平台的其中一个 PCIe Gen. 3 x16 插槽)。撇开英特尔至强可扩展处理器提供的系统性能不谈,这些扩展选件还可以在机箱外带来 100 Gbps 以太网带宽,用于连接大型 HPC 系统群集。
进一步扩展
虽然上述性能指标对于许多应用而言高不可攀,但是过去 50 多年的技术发展史告诉我们,对更强处理能力和更快网络的需求无处不在。对于开始规模很小的组织来说,英特尔至强金牌、银牌和铜牌处理器提供了允许将来扩展的入口点。
无论用在什么设备上,英特尔至强可扩展处理器家族都可提供当今时代 5G、大数据分析和 AI 应用所需的的计算、存储、虚拟化和网络基础设施 – 并提供采用未来任何支持技术之路。